HitSpooling for Supernova Alerts (HsProcessSuite)
The processing of hitspool data for supernova alerts is split into three levels: LowLevel, HighLEvel and AnaLevel. Source code of the automated processing tool can be found as HsProcessSuite in my sandbox .The various services are explained in the code and as an overview also in this GDrive folder.
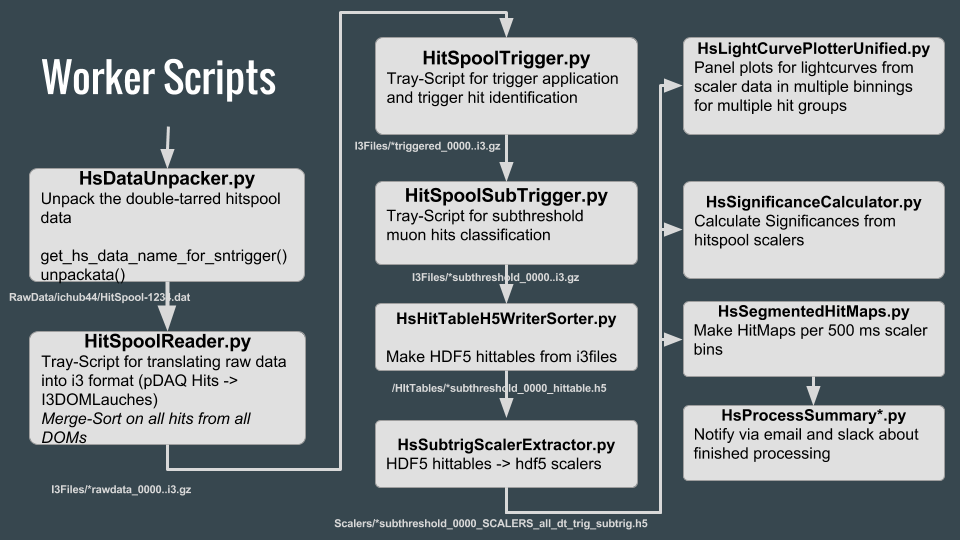
The above graphic explains the structure of the worker scripts that run the automated processing of hitspool data. Columns from left to right represent one processing level. These levels are also managed in three different DAGMan jobs on the condor cluster.
New data in the DHW is automatically detected through a scheduled cronjob on the submitter note. The wrapper routine for processing new data is HsProcessSuite.py
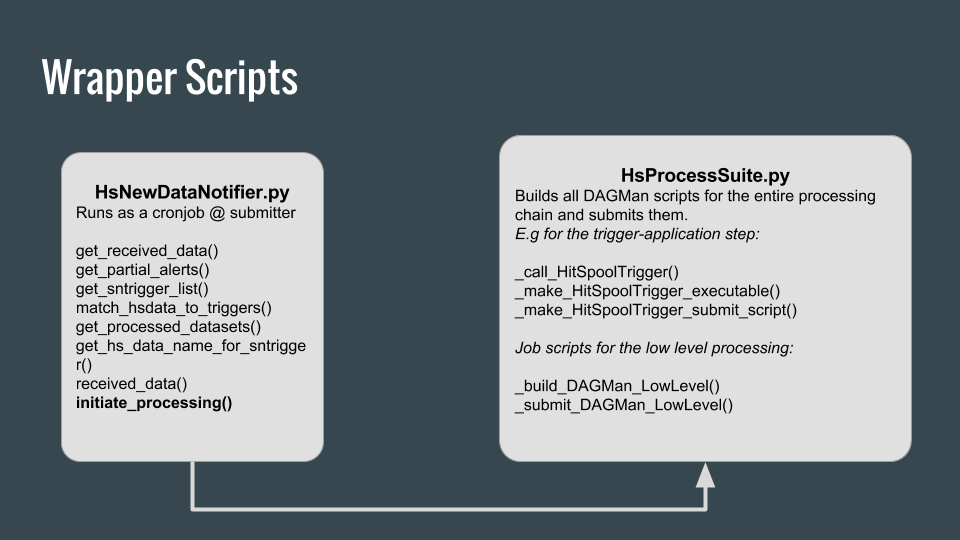
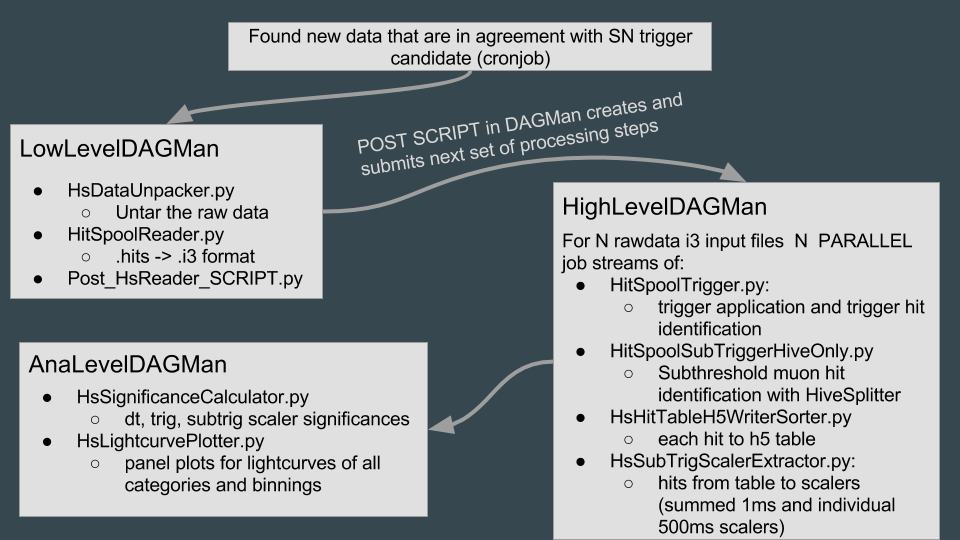
The wrapper script (HsProcessSuite.py) handles all three processing levels. It submits the processing jobs to the cluster with the help of DAGMan, a tool to facilitate multiple job management. The sructure of the DAGMan scripts is shown in the figure below.
Sn2ms fast scaler data processing (Sn2msHTML)
The 2ms scaler data is sent North via RUDICS in case of a supernova cadidate trigger with ξ > 7.6. This stream is fast because RUDICS has a 14/7 conncetion to the north. The limitation is bandwith and thus the 90000 scaler entries ([-30s, +60] around trigger time in 2ms wide bins) are sometimes chunked up in smaller peaces. The source code fo rdealing with these and producing the plots is in my sandbox.

Hitspool data fast analysis for supernova (HsAnaSuite)
Fast Analysis Test Page Explained
HitSpooling for HESE (HsHeseProcess)
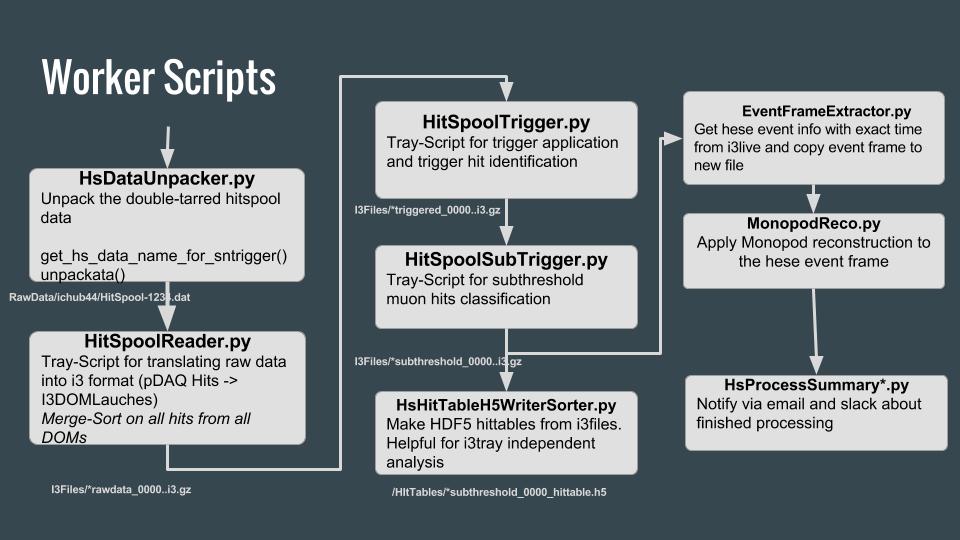
In great parallelism to the HsProcessSuite, hitspooling data for hese events is processed entirely the same until after the HighLEvel processing step (left and right column in the worker scripts figure above). Here is the source code.
Webpage Production (HsAnaHTML)
All these pages, main and details pages, are created by code located in the HsAnaHTML project. The project structure is shon in the following graphic.

The page is updated via a wrapper script that combines the various sub script that build the html pages.
