Executive summary of observations
Collection failures appeared and were resolved as follows. They tended to come in groups of 6, and there seems to be a correlation between decreased CPU (idle) use and resolution!
| Failed | Resolved |
| 0:10 | 0:22 |
| 4:07 | 4:32 |
| 4:07 | 4:33 |
| 4:07 | 4:33 |
| 4:07 | 4:34 |
| 4:07 | 4:34 |
| 4:07 | 4:34 |
| 4:18 | 4:35 |
| 4:18 | 4:35 |
| 4:53 | 5:19 |
| 4:53 | 5:20 |
| 4:53 | 5:19 |
| 4:53 | 5:21 |
| 4:54 | 5:21 |
| 4:55 | 5:20 |
| 5:46 | 6:14 |
| 5:47 | 6:14 |
| 5:48 | 6:14 |
| 5:49 | 6:14 |
| 5:50 | 6:14 |
| 5:50 | 6:15 |
| 13:07 | 13:19 |
| 13:46 | 14:04 |
| 18:19 | 18:50 |
| 18:20 | 18:50 |
| 18:22 | 18:52 |
| 24+00:48 | 24+1:08 |
| 24+00:48 | 24+1:08 |
| 24+6:59 | 24+7:17 |
| 24+6:59 | 24+7:17 |
| 24+7:00 | 24+7:18 |
| 24+7:01 | 24+7:18 |
| 24+7:01 | 24+7:19 |
| 24+7:01 | 24+7:19 |
| 24+8:30 | 24+8:49 |
| 24+20:27 | 24+20:43 |
| 24+20:28 | 24+20:43 |
| 24+20:28 | 24+20:43 |
| 24+20:29 | 24+20:43 |
| 24+20:29 | 24+20:43 |
| 24+22:48 | 24:23:10 |
So far failures have all resolved. Here's an example:
i$ grep 0110610044424 rfs.log 2011-06-10 04:44:24.057 I-410EA940: New collection files started for E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 04:45:14.684 I-42EEE940: Starting Load process for collection: E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 04:45:14.684 I-42EEE940: -- Starting PRIMARY SM write for collection /mnt/rfs_extra1/collections/E2004/E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU.dat to E2004_SYS 2011-06-10 04:55:24.789 E-42EEE940: Timeout attempting to create SM File: E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 04:55:24.789 E-42EEE940: -- UNSUCCESSFUL SM write to Primary System: E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 04:55:24.832 E-42EEE940: Unable to write collection: E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU to E2004_SYS. Error: Unable to create SMFile E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU on chuma.icecube.wisc.edu SM error: 9994 2011-06-10 04:55:24.832 I-42EEE940: Load process ended for collection E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 05:01:27.066 E-40FD0940: Timed out command 3 for collection E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU has completed with return code 0 2011-06-10 05:01:43.026 I-426E6940: Starting Load process for collection: E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 05:01:43.026 I-426E6940: -- Starting PRIMARY SM write for collection /mnt/rfs_extra1/collections/E2004/E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU.dat to E2004_SYS 2011-06-10 05:22:05.465 I-426E6940: -- Successful SM write to Primary System: E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU, 1786.9 MB at 1.5 MB/s (12.1 MB/s overall). 2011-06-10 05:22:05.529 I-426E6940: -- Starting PRIMARY load for /mnt/rfs_extra1/collections/E2004/E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU.ldr -- 2011-06-10 05:22:05.774 I-426E6940: -- Successful PRIMARY load: /mnt/rfs_extra1/collections/E2004/E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU.ldr System: E2004_SYS KB: 1745032 Collection: E2004_COLN Files: 145 2011-06-10 05:22:05.774 I-426E6940: Load process ended for collection E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 10:14:52.390 I-410EA940: Deleting local collection data for E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 10:14:52.390 I-410EA940: Deleting renamed files for E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU 2011-06-10 10:22:56.718 I-410EA940: Finished deleting renamed files for E2004_COLN20110610044424(C).SAM.ICECUBE.WISC.EDU
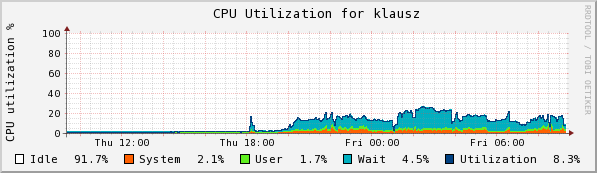
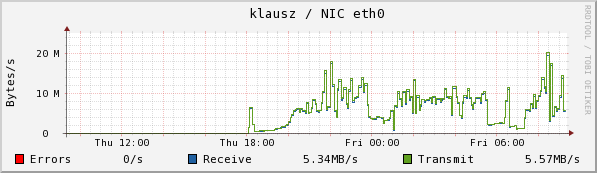
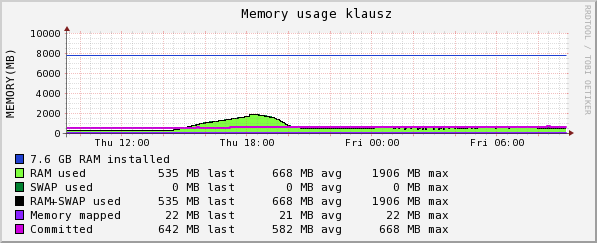
The copy was initiated on klausz, which mounts the /hsm from sam. Klausz shows the following CPU, Eth0, and RAM usage. I interpret the RAM usage as rsync creating its tables--note how long it takes to acquire 417,000 entries.
Sam accepts the input and processes the user files into collections. Here we see the CPU usage (note how much is idle!!), disk read and write, and Eth0 usage. It uses a bonded port to chuma, but only one channel is active.
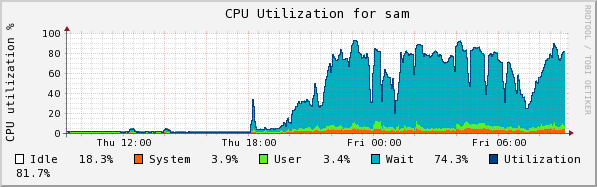
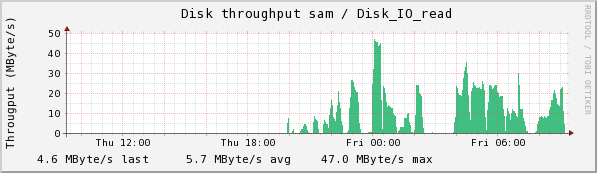
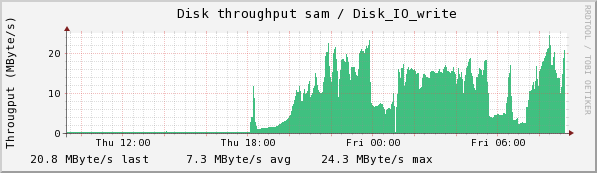
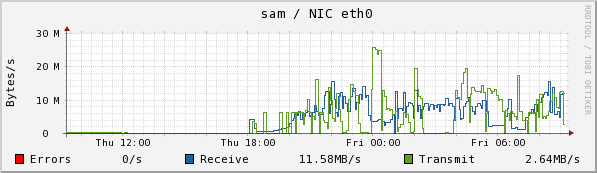
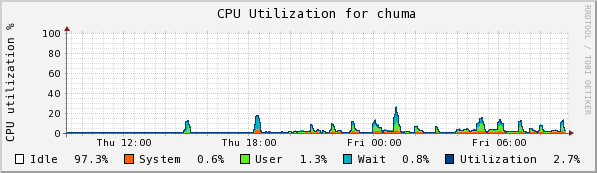
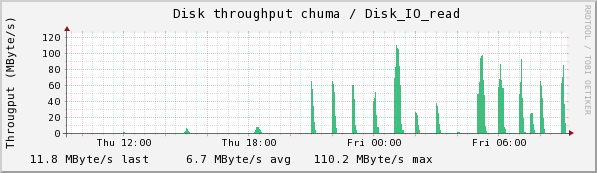
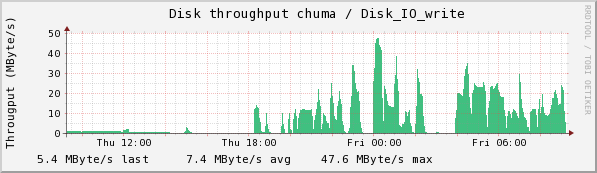
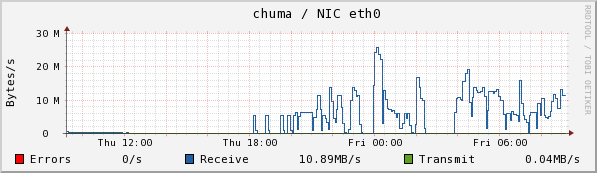
Chuma accepts the collections from sam and stores them. Here we see the CPU usage, disk read and write, and Eth0 usage.
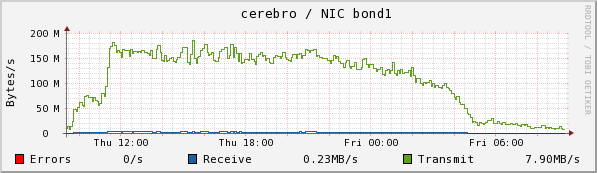
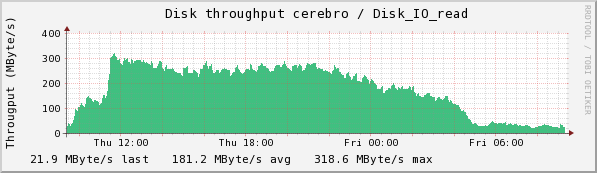
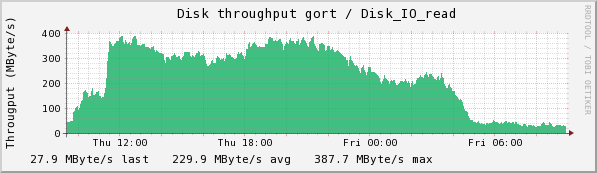
Cerebro and gort are two of the lustre servers serving /data/exp. Here we see the bond1 net usage for cerebro, the disk read rate for cerebro, and the disk read rate for gort.
And now the quantity of interest: the ingest rate. This isn't the entire AMANDA/2004 dataset, but a little over half of it. Nevertheless, we can see that the smaller files transmit at lower rate, that there is a lot of variation in transfer rate for files of the same size, and that the overall average speed is terrible: O(5MB/sec). The quantity "n" is the transfer number and may be used as a rough stand-in for time.
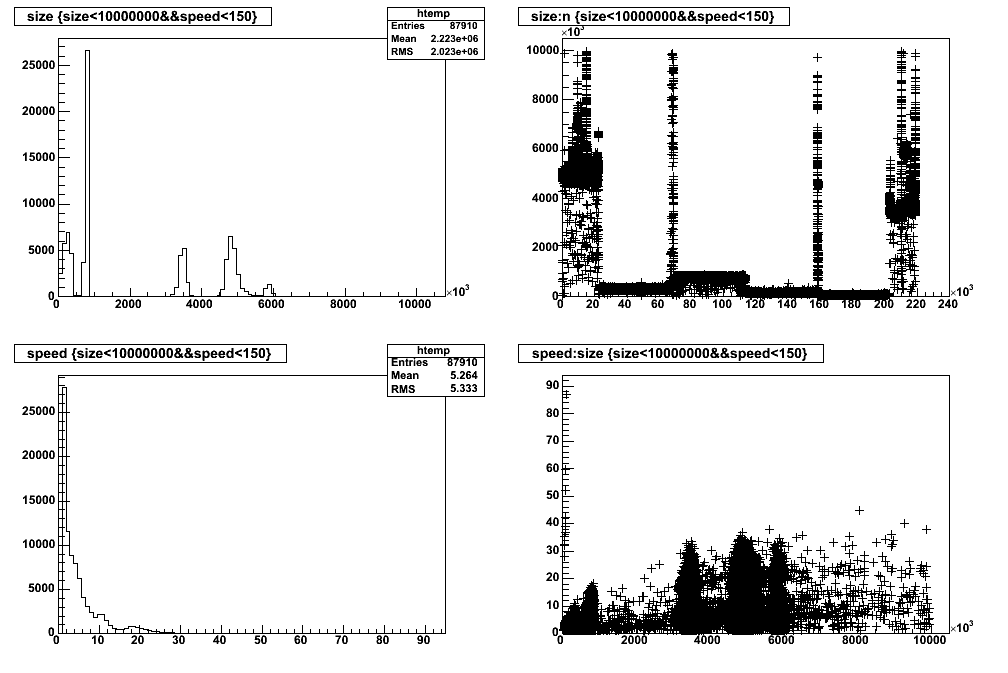
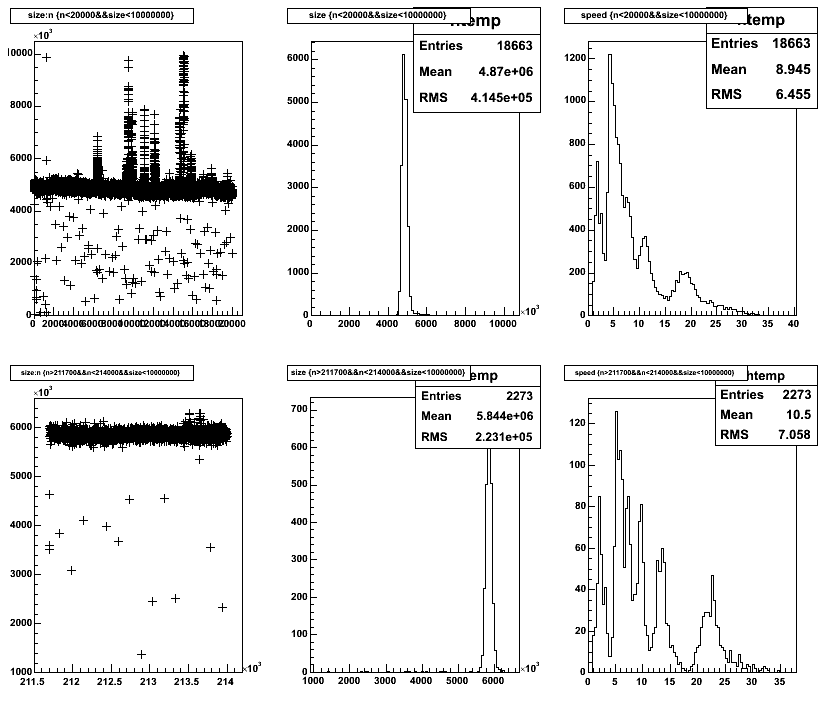
In particular, notice that despite the overall net usage declining, as shown in the cerebro et al plots, the transfer speed does _not_ increase for time intervals at the start (lower left) and end (lower right) of the period. The file sizes are somewhat smaller.
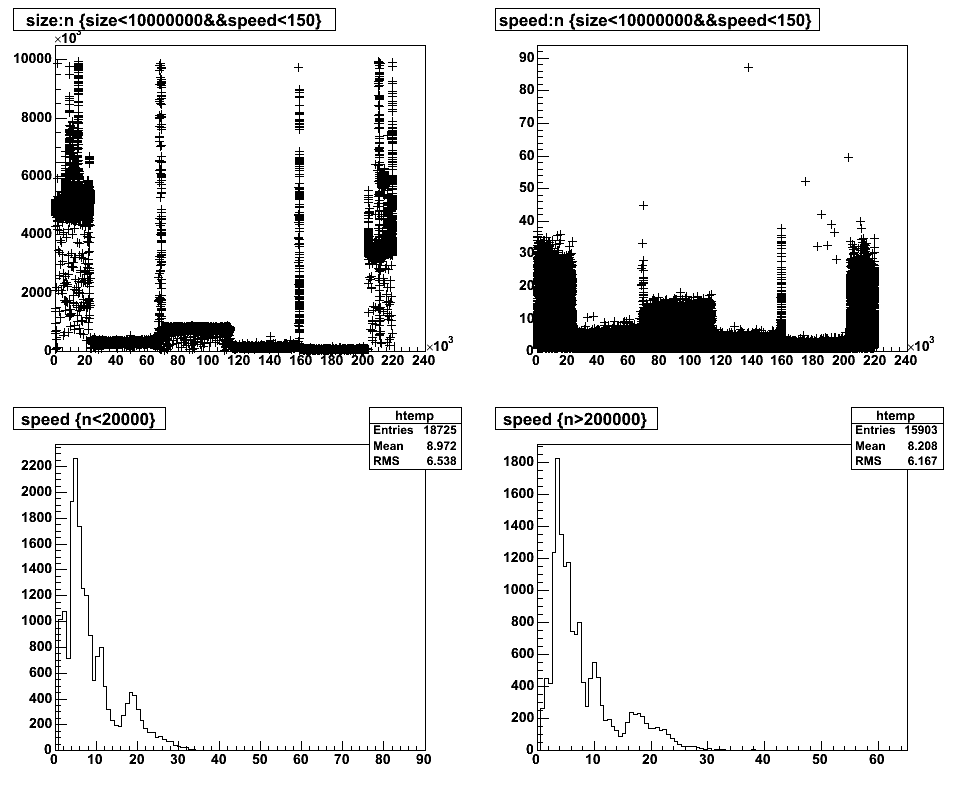
Getting more precise, we see that the early sizes average 4.64MB and transfer at a speed of 8.9MB/sec, and the late (less network contention) sizes average 5.56MB and transfer at a rate of 10.5MB/sec. These points display the linear behavior of speed to size, and show no evidence for improvement due to the better network bandwidth availability.
sent 1449819609664 bytes received 9110766 bytes 7202775.73 bytes/sec
I stopped RFS (generated a lot of fake errors, not listed about, for E2004_COLL as RFS shutdown: need to flush first next time) and created a new jnbtest_coll using the old fast disk array. The job finished quite quickly:
sent 1449908698362 bytes received 9110788 bytes 22403105.85 bytes/sec
I cannot view nagios results from outside 222, but if the lustre activity is the same as last Friday then there's no longer any question about the impact of disk speed on ingest speed.
Also note the difference in byte count. I find 245293 files referenced in the first (slow, punctuated with failures) copy, and 248043 in the second one.
Modified 10-June-2011 at 09:27
http://icecube.wisc.edu/~jbellinger/StorHouse/10Jun2011
| Previous notes | Next notes | Main slide directory |