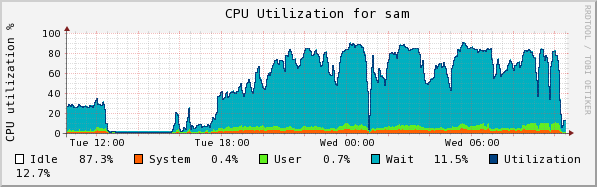
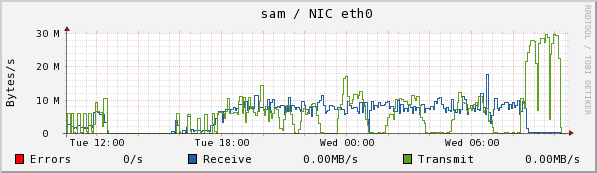
I halted the copy this morning in which I was testing E2004_COLL with 250GB for both the collection and collection. I found out what I was looking for: the larger space did not prevent "Unable to create SMFile ... on chuma" errors. I got 7 of them last night, at 12:07, 12:10, 12:12, 12:13, and at 12:25, 12:30, and at 3:16. Note the patterns in CPU usage and disk write and read on sam below:
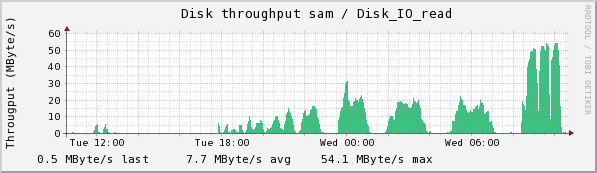
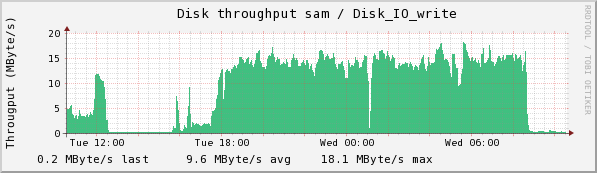
There is a strong dip in disk writes at about 1:00, which is when 4 of these resolved. There isn't an obvious pattern to when the failures occurred--it happens after the first peak in two of the double-peaked read humps, but there are double-peaks with no problems (as at 5:30). The spike at the right in disk reads and Eth0 transmits is due to the fact that I stopped the collection and requested a flush (ls /RFS/SM_LOCAL/SM_WRITE)
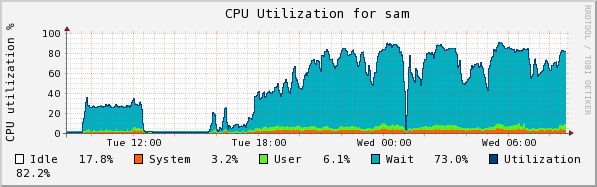
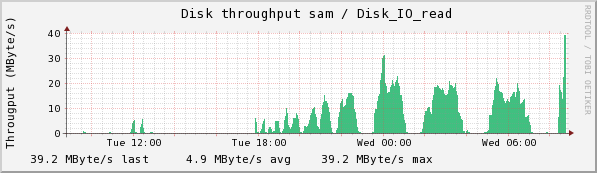
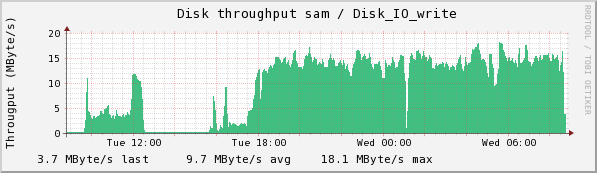
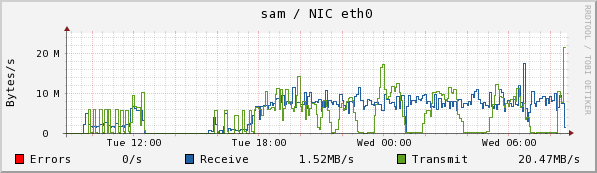
The following plots are the same ones taken some time after the flush finally finished. You can see a large jump in disk reads when there is no disk write contending with it, and see clearly 3 clumps of writes--the first of 31 collections, the second of 28, and the last of 23. Why these are clumped I do not know.
Modified 15-June-2011 at 08:50
http://icecube.wisc.edu/~jbellinger/StorHouse/15Jun2011
| Previous notes | Next notes | Main slide directory |