2005 AMANDA Point Source Analysis
Simulation
Event Selection
Methodology
Sensitivity, Discovery Potential, & Systematics
Unblinding Proposal
Results
Questions and Answers
 |
| NASA/ESA Hubble |
Event Selection
Optimization is accomplished by minimizing the MRF (optimizing for sensitivity) of a binned point search. While it would generally be preferable to optimize using the final search method of the analysis, it is technically difficult to do with the method proposed for this analysis. Development an algorithm to accomplish this optimization is ongoing. Optimization is done by brute force, simultaneously optimizing all parameters.
The Cuts
 |
 |
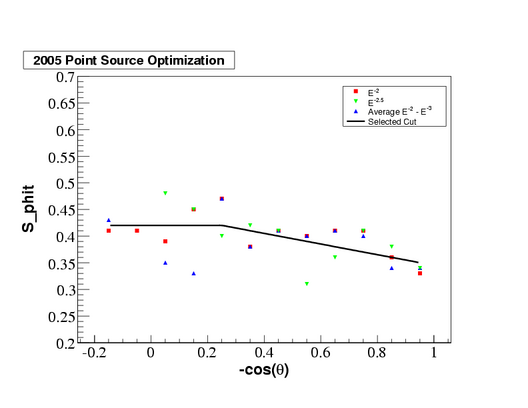 |
 |
 |
 |
Cut Expressions
| Likelihood ratio | Jkchi[Bayesian64]-Jkchi[Pandel] > 33 - 33.3*Theta(0.15-x)*(0.15-x) + 5*Theta(x-0.15)*(x-0.15) |
| Paraboloid error | 180/PI * sqrt(err1*err2) < 4.4 - 3.4*Theta(0.35-x)*(0.35-x) - 2.333*Theta(x-0.35)*(x-0.35) |
| Smoothness | abs(S_phit) < 0.42 - 0.1*Theta(x-0.25)(x-0.25) |
| Direct length | Ldirb[Pandel] > 38 + 96*Theta(x-0.7)*(x-0.7) |
| Flare variables | TOT_short + B10 + nB10 < 10 |
The Final Event Sample
Application of the cuts on time-scrambled data results in 6001 events above 80 degrees zenith, a significant portion downgoing muons near 80 degrees. 3 events have negative paraboloid errors and were removed, leaving 5998. Above 100 degrees, 887 data events remain (on 1013 atmospheric neutrino events).
Muon neutrino effective area agrees with previous analyses. Error bars indicate the statistical error in effective area from MC.
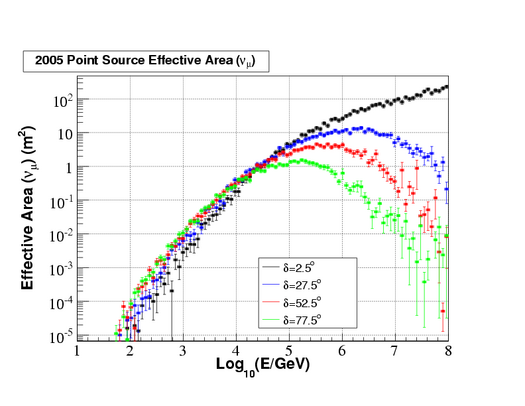 |  |
Normalization
The usual procedure of tightening cuts until the ratio data/MC levels is applied at zenith > 100, obtaining a normalization factor of 0.82. The amount of background present in the final sample above 100 degrees is ~6.5%.

Distribution of cut parameters (Zenith > 100)
 |
 |
 |
 |

MC Scaling
It is clear S_phit is underestimated in the atmospheric neutrino MC. S_phit distributions for downgoing muon data are compared with dCORSIKA.
A scale factor of 1.08 brings S_phit into much better agreement with data, consistent with the 2000-2003 diffuse analysis. Scaling Atmospheric neutrino MC by 1.08 reduces sensitivity by <1% for all zenith ranges, so the chosen cuts do not need to be adjusted.
It is clear paraboloid error is also underestimated at values less than 3.0 degrees.

Since the proposed cuts are beyond the region of strong disagreement, we can ignore the differences between data and MC.