PISA stage modes¶
Every PISA stage of a pipeline has a calc_mode and an apply_mode. Both instance attributes specify the “representation” in which generic data (e.g., neutrino MC events) is processed through the pipeline. Often calculations can be faster when performed on grids, but we need to be careful in order to ensure that we are not introducing large errors.
More specifically, calc_mode by default defines the representation during the setup()and compute() steps, and apply_mode that during the apply step, see the stages readme. The latter two steps are executed successively whenever a given stage instance is run(), during the pipeline output calculation. Like this, complex event-by-event calculations (e.g., oscillation probabilities) can for example be executed during the compute() step, which also has a basic caching mechanism to avoid redundant calculations. The apply() step typically performs simple transformations (using results of a preceding compute() step or not) of the data in the representation determined by apply_mode. Take a look at different stage implementations (“services”) and example pipeline configuration files to get a better feel for the concept.
Note that you can change the modes on runtime, but after doing so need to setup() the stage or pipeline again (exercise: can you find a service which only defines its setup() step, but neither compute() nor apply()?).
If the output representation of a stage is different than what, for example, the next stage needs to have as input, the output is automatically translated by PISA (translation between data representations). So you can mix and match, but be aware that translations will introduce computational cost and hence may slow things down.
import numpy as np
import matplotlib.pyplot as plt
from pisa.core.pipeline import Pipeline
<< PISA is running in double precision (FP64) mode; numba is running on CPU (single core) >>
We will configure our neutrino pipeline in 3 different ways:
The standard form with some calculation on grids
All calculations on an event-by-event basis (the most correct, but by far slowest way)
All calculations on grids (usually faster for large event samples)
mixed_modes_model = Pipeline("settings/pipeline/IceCube_3y_neutrinos.cfg")
mixed_modes_model.profile = True
events_modes_model = Pipeline("settings/pipeline/IceCube_3y_neutrinos.cfg")
events_modes_model.profile = True
events_modes_model.stages[1].calc_mode = "events"
events_modes_model.stages[2].calc_mode = "events"
events_modes_model.stages[3].calc_mode = "events"
events_modes_model.setup()
grid_modes_model = Pipeline("settings/pipeline/IceCube_3y_neutrinos.cfg")
grid_modes_model.profile = True
true_binning = grid_modes_model.stages[1].calc_mode
grid_modes_model.stages[0].apply_mode = true_binning
grid_modes_model.stages[1].apply_mode = true_binning
grid_modes_model.stages[2].apply_mode = true_binning
grid_modes_model.stages[3].apply_mode = true_binning
grid_modes_model.stages[4].apply_mode = true_binning
grid_modes_model.stages[4].calc_mode = true_binning
grid_modes_model.stages[5].calc_mode = true_binning
grid_modes_model.setup()
mixed_modes_model
| stage number | name | calc_mode | apply_mode | has setup | has compute | has apply | # fixed params | # free params |
|---|---|---|---|---|---|---|---|---|
| 0 | csv_loader | events | events | True | False | True | 0 | 0 |
| 1 | honda_ip | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | events | True | True | False | 1 | 0 |
| 2 | barr_simple | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | events | True | True | False | 1 | 4 |
| 3 | prob3 | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | events | True | True | True | 9 | 3 |
| 4 | aeff | events | events | False | False | True | 2 | 3 |
| 5 | hist | events | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | True | False | True | 0 | 0 |
| 6 | hypersurfaces | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | True | True | True | 0 | 5 |
events_modes_model
| stage number | name | calc_mode | apply_mode | has setup | has compute | has apply | # fixed params | # free params |
|---|---|---|---|---|---|---|---|---|
| 0 | csv_loader | events | events | True | False | True | 0 | 0 |
| 1 | honda_ip | events | events | True | True | False | 1 | 0 |
| 2 | barr_simple | events | events | True | True | False | 1 | 4 |
| 3 | prob3 | events | events | True | True | True | 9 | 3 |
| 4 | aeff | events | events | False | False | True | 2 | 3 |
| 5 | hist | events | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | True | False | True | 0 | 0 |
| 6 | hypersurfaces | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | True | True | True | 0 | 5 |
grid_modes_model
| stage number | name | calc_mode | apply_mode | has setup | has compute | has apply | # fixed params | # free params |
|---|---|---|---|---|---|---|---|---|
| 0 | csv_loader | events | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | True | False | True | 0 | 0 |
| 1 | honda_ip | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | True | True | False | 1 | 0 |
| 2 | barr_simple | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | True | True | False | 1 | 4 |
| 3 | prob3 | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | True | True | True | 9 | 3 |
| 4 | aeff | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | False | False | True | 2 | 3 |
| 5 | hist | "true_allsky_fine": 200 (true_energy) x 200 (true_coszen) | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | True | False | True | 0 | 0 |
| 6 | hypersurfaces | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | "dragon_datarelease": 8 (reco_energy) x 8 (reco_coszen) x 2 (pid) | True | True | True | 0 | 5 |
We can compare timings. Event-by-event it takes around 8 minutes! The two other modes around 25 seconds.
%%time
events = events_modes_model.get_outputs()
CPU times: user 7min 28s, sys: 349 ms, total: 7min 28s
Wall time: 7min 28s
%%time
mixed = mixed_modes_model.get_outputs()
CPU times: user 23.5 s, sys: 51.9 ms, total: 23.6 s
Wall time: 23.6 s
%%time
grid = grid_modes_model.get_outputs()
CPU times: user 26.5 s, sys: 3.95 s, total: 30.4 s
Wall time: 23.7 s
We can see that in this configuration we probably have fine enough grids, such that differences are at the sub-percent level. This may or may not be acceptable for the specific analysis you want to do.
fig, ax = plt.subplots(2, 3, figsize=(20, 7))
plt.subplots_adjust(hspace=0.5)
e = events.combine_wildcard('*')
m = mixed.combine_wildcard('*')
g = grid.combine_wildcard('*')
e.plot(ax=ax[0,0], title="Events")
m.plot(ax=ax[0,1], title="Mixed")
((e - m)/e).plot(ax=ax[0,2], symm=True)
e.plot(ax=ax[1,0], title="Events")
g.plot(ax=ax[1,1], title="Grid")
((e - g)/e).plot(ax=ax[1,2], symm=True)
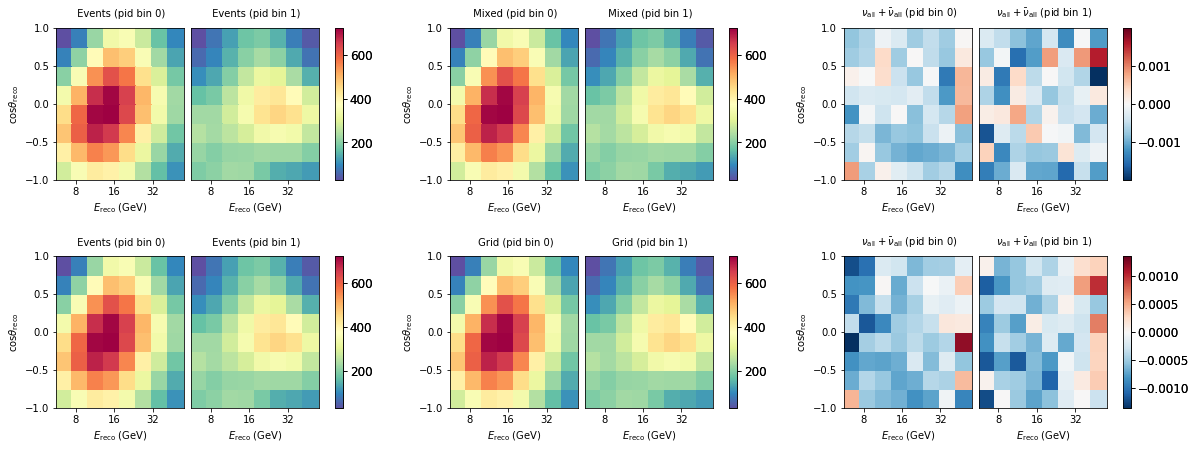
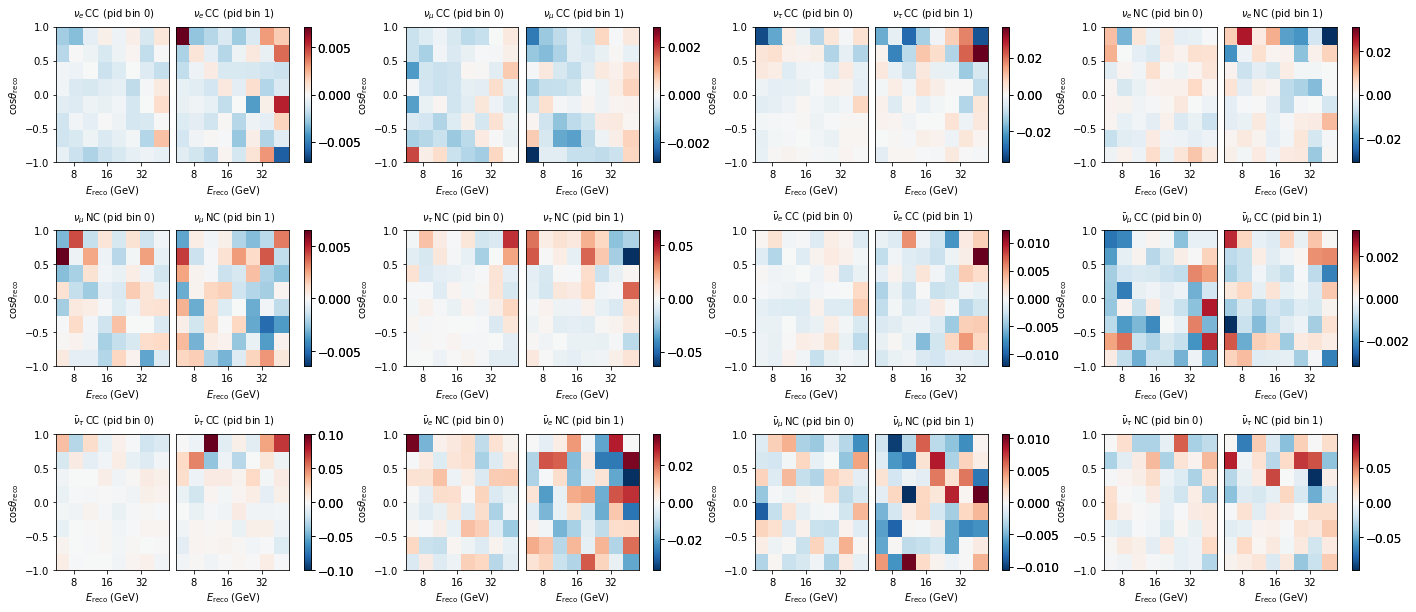
In depth comparison of single maps:
fig, axes = plt.subplots(3,4, figsize=(24,10))
plt.subplots_adjust(hspace=0.5)
axes = axes.flatten()
diff = (events - mixed) / (events + 1e-7)
for m, ax in zip(diff, axes):
m.plot(ax=ax, symm=True)
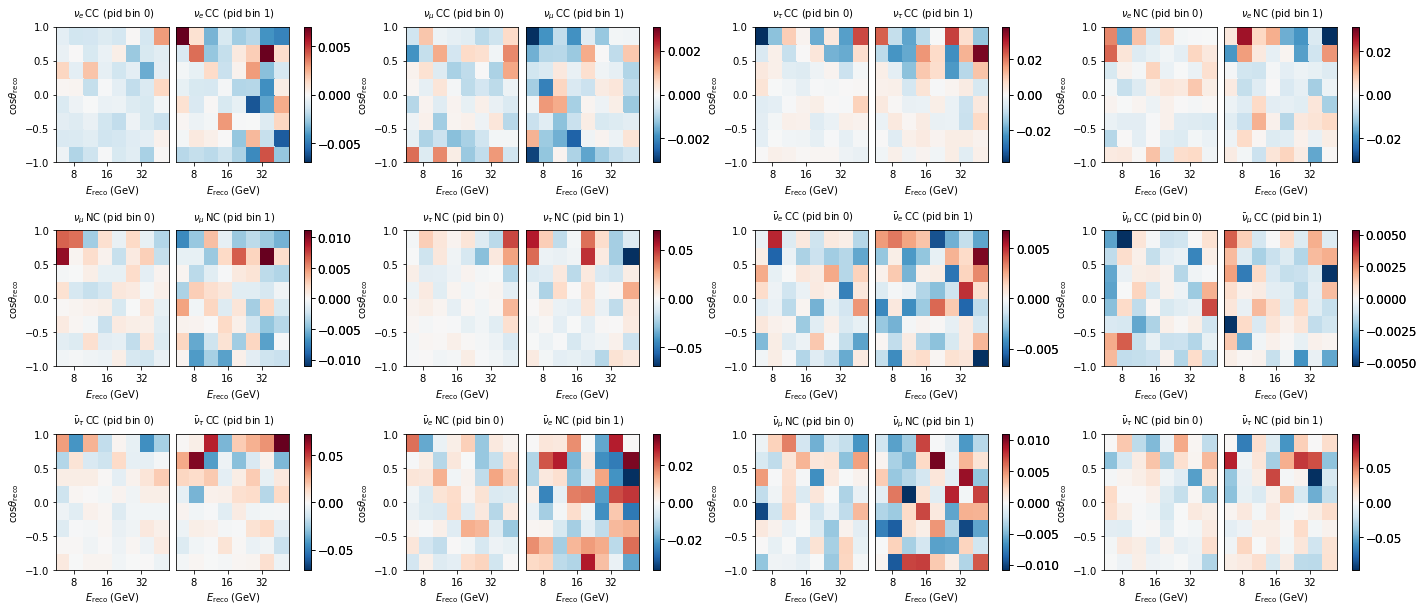
fig, axes = plt.subplots(3,4, figsize=(24,10))
plt.subplots_adjust(hspace=0.5)
axes = axes.flatten()
diff = (events - grid) / (events + 1e-7)
for m, ax in zip(diff, axes):
m.plot(ax=ax, symm=True)