Unfolding¶
The Concept of Unfolding¶
The quantity of interest, the propagation length of the particles, is smeared out in the detection process due to the limited accuracy and sensitivity of the detector. Hence, it is impossible to determine the physical truth from the measurement directly. In fact, the measurement yields proxy variables, which stem from the detector response to the underlying physics. The inverse process, namely the determination of the most probable physical truth on the basis of the measurements, is referred to as unfolding.
The distribution of a measured quantity \(g(y)\) is connected to the true physical distribution \(f(x)\) via the detector response \(A(x,y)\) according to the convolution integral
This is referred to as the Fredholm integral equation of the first kind. The additional term \(b(y)\) represents some bias, which originates form contributions to the measurement that are considered as background. Since the selected sample is assumed to have a sufficiently high purity, the bias will be neglected in the following. The quantity \(\epsilon(y)\) denotes systematic uncertainties, which are not yet taken into account. The detector response function \(A(x,y)\) describes the whole detection procedure. It depends on the physical truth and has to be determined from Monte Carlo simulations.
In practice, it is necessary to discretize the phase space of the variables \(x\) and \(y\). The integral has to be transformed into a sum
where the equation on the right represents a matrix multiplication with the detector response matrix \(\textbf{A}\) and the vectors \(\textbf{g}\) and \(\textbf{f}\). Each vector component denotes a bin entry in the distribution of the corresponding quantity.
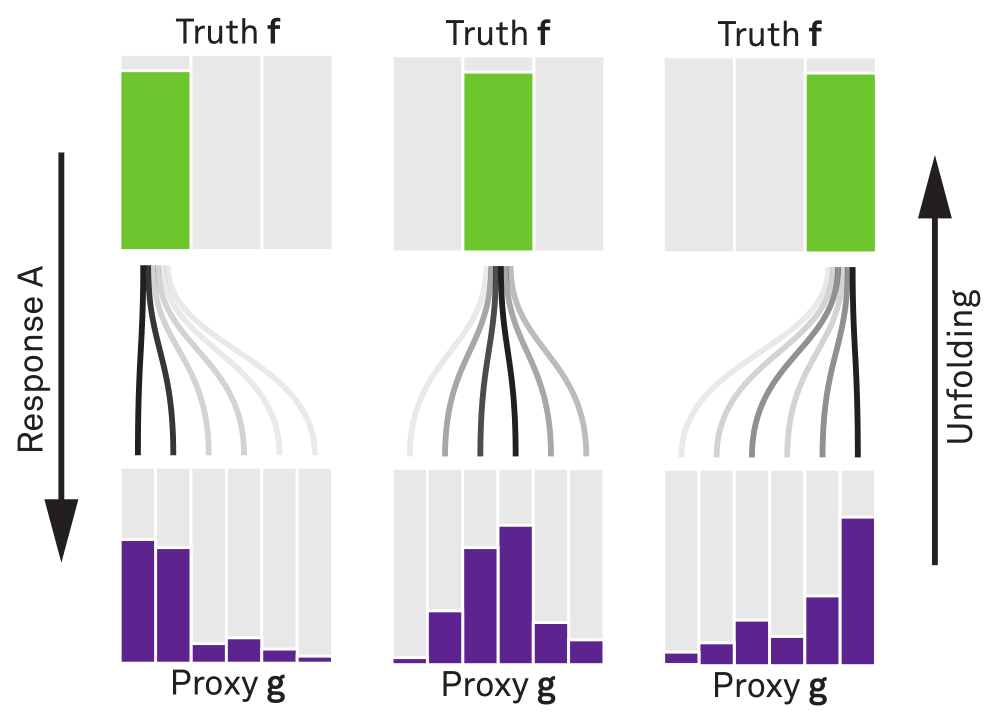
Fig. 43 : Schematic representation of unfolding. The underlying physical truth is smeared in the detection process. This is described by the detector response \(A\). The inverse process, which determines the most probable physical truth on the basis of the measurements, is called unfolding.¶
The main task is the reconstruction of the true distribution \(\textbf{f}\) from the measured distribution \(\textbf{g}\). In principle, this could be done by simply inverting the discrete Fredholm equation. However, the response matrix is not necessarily a square matrix and even if the inverse \(\textbf{A}^{-1}\) exists, the solution often shows an oscillating behavior. This would be an unphysical result and can be traced back to the properties of the matrix itself. The approach is an ill-posed problem, where small eigenvalues of the matrix heavily amplify statistical noise in the measurement. Consequently, more sophisticated methods are needed to unfold the true spectrum.
Maximum Likelihood Estimation¶
One such approach is a maximum likelihood estimation. A likelihood function is constructed by assuming a Poisson distribution for each bin of the proxy variable
where the used model \(\lambda_{i}(\textbf{f}\,)\) corresponds to the discrete Fredholm equation
The most probable distribution \(\textbf{f}\) on the basis of the measurements \(\textbf{g}\) maximizes the likelihood. For practical reasons, it is often useful to minimize the negative logarithm of this function instead. The result remains unchanged, but the likelihood reads
The complication of oscillating solutions still remains. To overcome this problem, it is necessary to introduce additional assumptions about the smoothness of the distribution. This method is referred to as regularization. A commonly used form of regularization is the Tikhonov regularization. It introduces a penalty term which suppresses high second derivatives of the solution
with the regularization matrix
It is chosen such that \(\textbf{C} \textbf{f}\) is the second derivative according to the finite difference method. The parameter \(\tau\) controls the strength of the regularization. Introducing a regularization serves as a form of bias. It is important to optimize its strength in such a way that the oscillations are suppressed, but the spectrum is not flattened to an extent that makes the result physically unreliable. The total likelihood then reads
Since bins of the target distribution \(\textbf{f}\) can be empty and the logarithm of zero is not definded, a small offset \(d\) is added. The target distribution is further subject to the detector response, which is why not \(\textbf{f}\) itself, but the logarithm of the acceptance corrected spectrum is expected to be flat. Hence, the regularization term is modified:
funfolding¶
The concepts of ML unfolding have already been implemented in a python package by Mathis Börner, a former member of the
TU Dortmund group. The package is available via pip install funfolding. In addition to the above mentioned unfolding
approach, the package features tools such as an MCMC sampling or the possibility of fitting nuisance parameters to
the distributions, which improves the estimation of systematic uncertainties in the analysis. Funfolding has also been
used in an earlier IceCube analysis (3yr NuMu analysis) where
additional informaiton can be found.
MCMC Sampling¶
Funfolding evaluates the likelihood in a bayesian approach. A Markov Chain Monte Carlo (MCMC) sampling is used to contruct an a-posteriori distribution of the form
where the a-priori distribution of \(\textbf{f}\) is set to be uniform
The drawn samples depend only on the one sampled before them, and they are independent of all others. Starting from a random guess, the chain moves to another point by adding a noise from a predetermined distribution. The jump is accepted with a certain probability, following the concepts of a modified Metropolis-Hastings algorithm as implemented in the \(\texttt{EnsembleSampler}\) of the \(\texttt{emcee}\) python package. The new point is included in the sample.
Parameter Optimization¶
The regularization strength \(\tau\) and the log-offset \(d\) have to be optimized. This is done by means of a simple grid search which aims to minimize the chi-squared distance between the unfolded result (on MC data) and the MC truth. The following metric is calculated for the individual unfoldings:
Systematic Uncertainties¶
Certain parameters in the simulation chain have uncertainties, which is why it is necessary to estimate their impact on the analysis as so-called systematic uncertainties. In terms of unfolding, the systematics are described by systematic parameters, which are fitted to the data as additional nuisance parameters. The detector repsonse matrix then depends on these additional parameters:
For each systematic, new simulation sets are used. These simulation sets are created with the systematic parameters variing within their defined range. This enables to construct weighting functions \(\omega_{i}(\xi_{j})\) (\(i\): Bin, \(j\): Systematic) that present the relative change of the bin content compared to the baseline simulation. To consider all parameters in a single bin, the functions are multiplied
The response matrix is then calculated as
The likelihood \(\mathcal{L}\) now also depends on the nuisance parameters \(\vec{\xi}\), which makes it possible to fit these parameters in the unfolding.
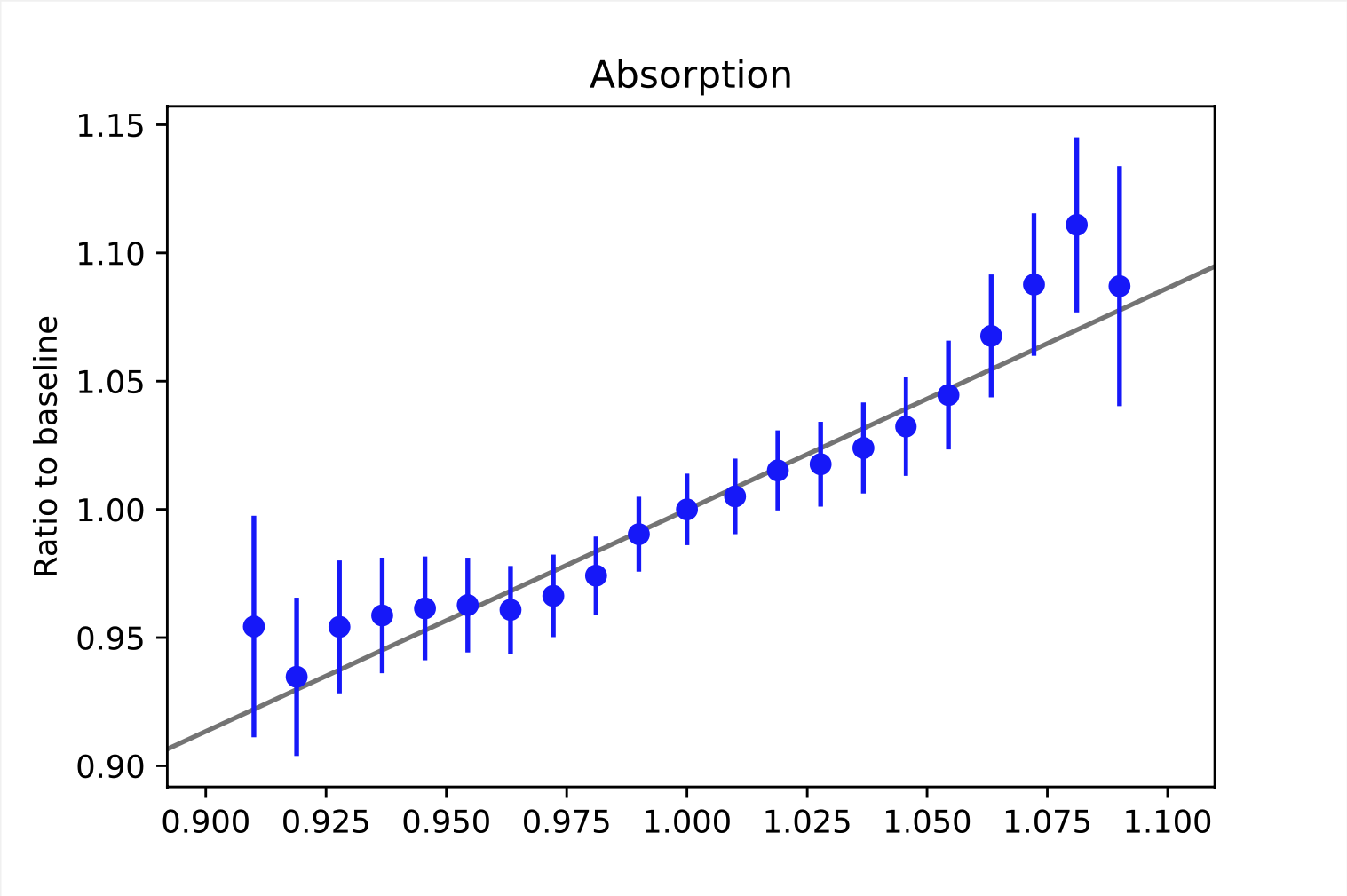
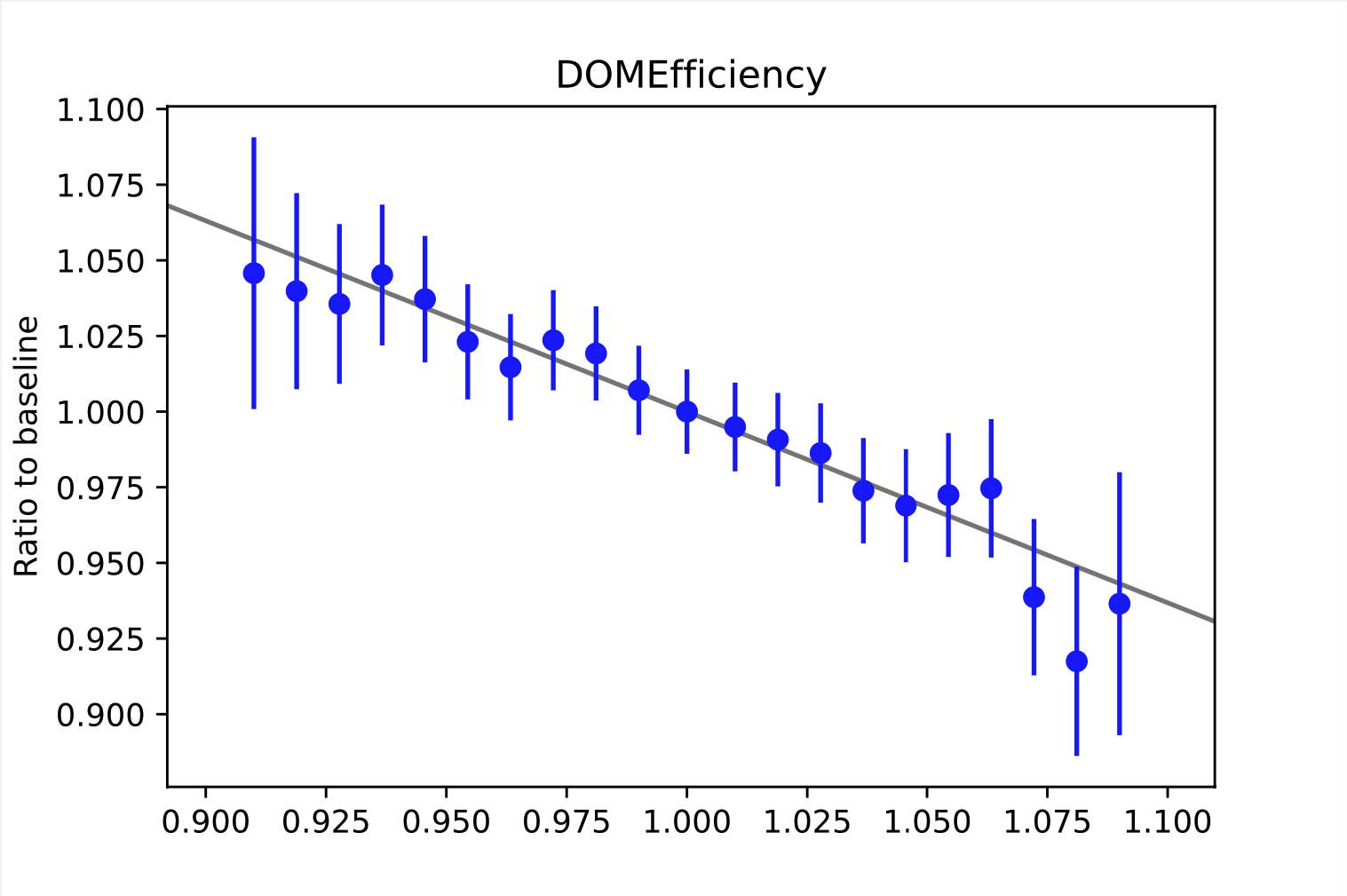
Some examples of weighting functions are shown below. As mentioned above, the weighting functions describe the relative change of the bin content. This refers to the bins of the observable space. Here, the examples are taken from random bins in the depth intensity unfolding, so they describe the change in the MC distribution (y-axis) based on the choice of the systematic parameters (x-axis). For energy unfolding, the concept remains the same. The baseline value for the systematic parameter depends on the exact systematic that is to be described. The baseline value always corresponds to the point where the ratio equals one. In order to interpolate between the data points, the ratio is fitted. The resulting function resemples the weighting function \(\omega_{i}(\xi_{j})\).
It is necessary to determine these ratios on MC data, since the information about the change of the true target quantity is needed. As far as we know, there are no systematic data sets for the 20904 set. Thus, we used our self-simulated data (58500/57500, see Table 2) that was simulated with snowstorm to construct the weighting functions. An advantage of snowstorm simulations is the possibility of creating a wide range of grid points, making the description more accurate.

_bin_3.png)
_bin_3.png)
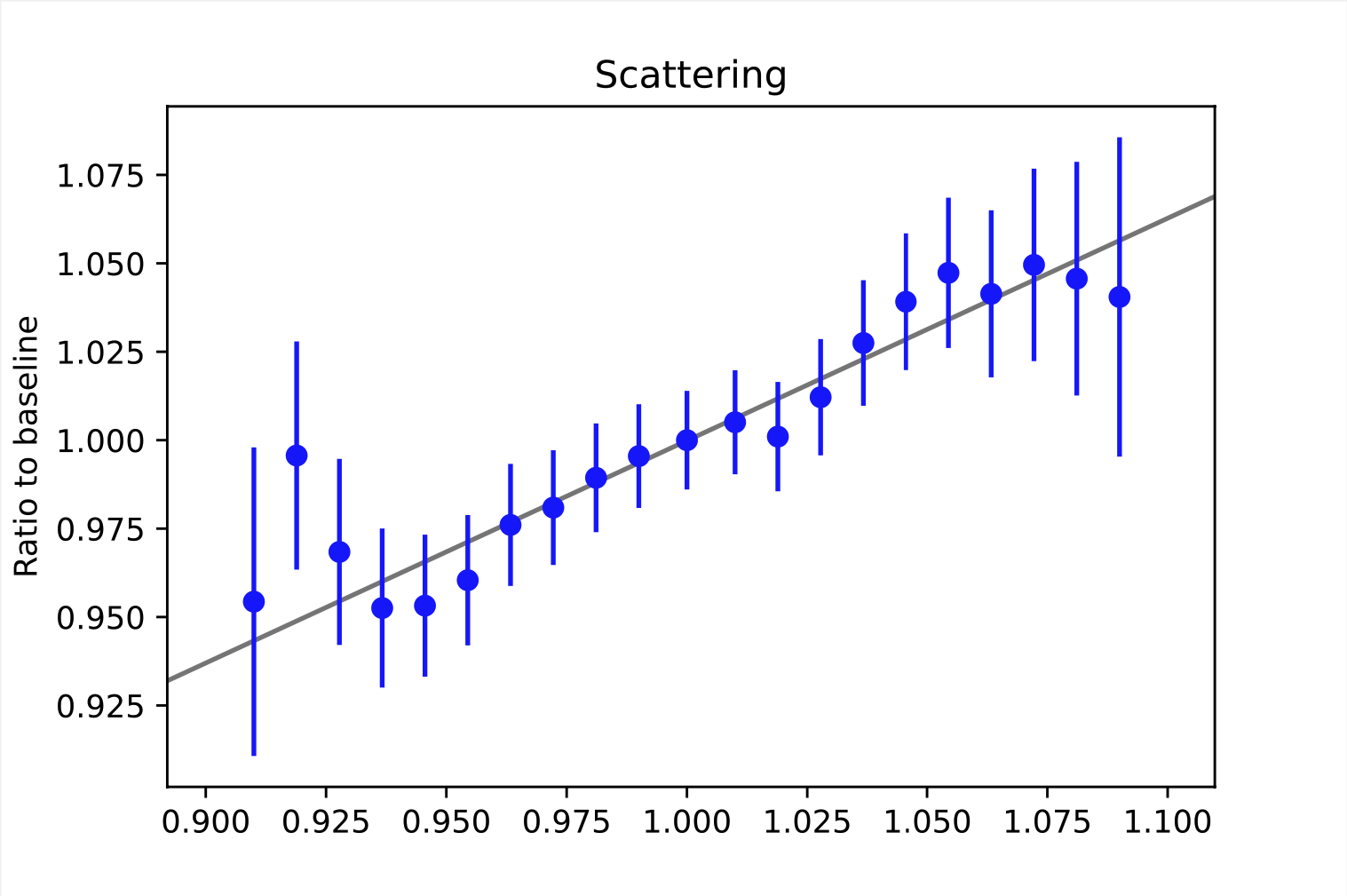
All systematics, except for the second HoleIce parameter, can be fitted with a linear funciton.
In additon to the in-ice systematics we also consider the impact different flux models. Further details about their impact are discussed in the Systematic Checks section.